数据的搜索
1. 实验介绍
1.1 实验内容
在本节实验中,我们将介绍一些数据查询方式,条件匹配等内容
1.2 实验知识点
- 查询
- 运算符和表达式
- 函数
- 分组排序
2. 示例表
2.1 示例表
在开始本节实验之前,我们需要先创建三张表,并插入一些数据,用作演示用例,这里我们使用比较常见的选课数据库,如下的三张表:
学生表(student):
| 学号(s_id) | 姓名(s_name) | 性别(s_sex) | 年龄(s_age) |
|---|---|---|---|
| 1001 | shiyanlou1001 | man | 10 |
| 1002 | shiyanlou1002 | woman | 20 |
| 1003 | shiyanlou1003 | man | 18 |
| 1004 | shiyanlou1004 | woman | 40 |
| 1005 | shiyanlou1005 | man | 17 |
课程表(course):
| 课程号(c_id) | 课程名(c_name) | 课时(c_time) |
|---|---|---|
| 1 | java | 13 |
| 2 | python | 12 |
| 3 | c | 10 |
| 4 | spark | 15 |
选课表(sc):
| 学号(s_id) | 课程号(c_id) | 成绩(grade) |
|---|---|---|
| 1001 | 3 | 70 |
| 1001 | 1 | 20 |
| 1002 | 1 | 100 |
| 1001 | 4 | 96 |
| 1002 | 2 | 80 |
| 1003 | 3 | 75 |
| 1002 | 4 | 80 |
上述表即为用于我们查询操作的示例表。
2.2 执行 sql 语句的方式
在前面的内容中,我们通过客户端连接到服务端,并使用客户端提供的交互式 shell 运行 sql 语句。除此之外,如果需要执行 sql 语句,我们还有其它常用的两种方式:
- 将 sql 语句放入文件中,批量执行
- 使用 mysql 客户端程序的 -e 参数
下面我们简单介绍这两种方式,首先我们可以将要执行的 sql 语句放入一个文件中,该文件可以通过如下方式进行下载:
$ wget http://labfile.oss.aliyuncs.com/courses/980/files/week7/exec_sql.txt
文件中包含我们创建示例表的 sql 语句,查看该文件如下所示:
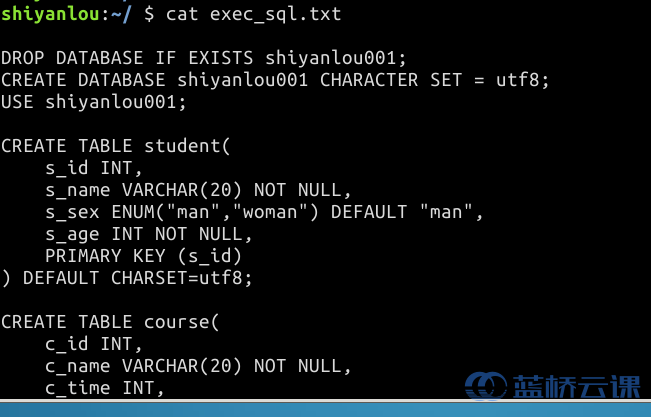
下载完成后需要告诉 mysql 读取其中的语句并执行,使用如下命令:
$ mysql -u root -p < exec_sql.txt
其执行结果如下所示:

或者我们还可以在交互式下使用 source 来执行文件中的命令,采用如下方式:
mysql> source exec_sql.txt
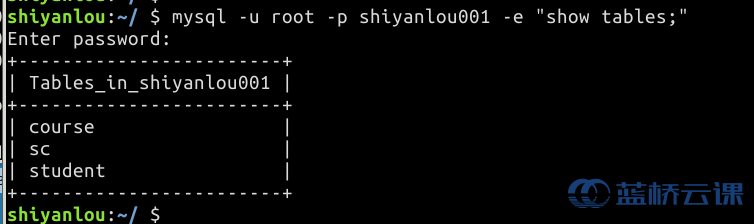
此时,示例表就已经创建成功了,最后我们使用 mysql 的 -e 参数来执行查看的命令,使用如下方式:
$ mysql -u root -p shiyanlou001 -e "show tables;"
3. 查询
通过上面的步骤成功创建示例表之后,我们就可以开始学习查询相关的操作了
在前面的内容中我们有使用 SELECT 进行一些简单的表达式计算操作,或者与一些函数搭配使用,除此之外 SELECT 最重要的是进行查询操作。
一个简单的查询语法如下所示:
SELECT select_expr [,select_expr ...] FROM tbl_name [WHERE where_condition]
3.1 select_expr
这里的 select_expr 一般代指 col_name,即字段,但是除了字段之外,还有一些其它的内容,如函数等。而前面我们经常使用的星号 * 则代指所有字段。
对于 select_expr 我们可以设定别名,用于查询结果的列名,并且可以在一些子句中使用,相关的语法如下:
SELECT select_expr [AS] full_name
这里的 full_name 则代表我们将要起的别名,[AS] 是可选项,但是为了增加可读性,一般我们会使用 [AS]。如下的简单示例,我们可以看到结果的列名被修改:
mysql> SELECT time("123456");
+----------------+
| time("123456") |
+----------------+
| 12:34:56 |
+----------------+
1 row in set (0.11 sec)
mysql> SELECT time("123456") now;
+----------+
| now |
+----------+
| 12:34:56 |
+----------+
1 row in set (0.01 sec)
mysql> SELECT time("123456") AS now;
+----------+
| now |
+----------+
| 12:34:56 |
+----------+
1 row in set (0.00 sec)
mysql>
3.2 FROM
在上述格式中我们看到了 FROM 关键字,该关键字用于指定我们所要查询的数据表。
如下关于查询的示例。我们查看 student 表中的姓名和年龄。
mysql> SELECT s_name,s_age FROM student;
+---------------+-------+
| s_name | s_age |
+---------------+-------+
| shiyanlou1001 | 10 |
| shiyanlou1002 | 20 |
| shiyanlou1003 | 18 |
| shiyanlou1005 | 40 |
| shiyanlou1005 | 17 |
+---------------+-------+
5 rows in set (0.00 sec)
mysql>
3.3 WHERE
在上述格式中我们看到了 WHERE 关键字,该关键字用于指定我们所要查询的数据字段的限定条件。
例如查询 student 表中性别为 man 的学生:
mysql> SELECT * FROM student WHERE s_sex="man";
+------+---------------+-------+-------+
| s_id | s_name | s_sex | s_age |
+------+---------------+-------+-------+
| 1001 | shiyanlou1001 | man | 10 |
| 1003 | shiyanlou1003 | man | 18 |
| 1005 | shiyanlou1005 | man | 17 |
+------+---------------+-------+-------+
3 rows in set (0.05 sec)
mysql>
4. 运算符和表达式
在上面的示例中,我们使用了 WHERE 子句,例如 WHERE s_sex="man"。除了 = 符号之外,还有一些其它的操作符。 如下:
用于比较值
| 操作符 | 释义 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| BETWEEN… AND... | 检查值的范围 |
| IN | 检查是否在一组值中 |
| NOT IN | 检查一个值是否不在一组值中 |
| IS {TRUE 或 FALSE} | 判断 bool 值 |
| IS NULL | NULL 值测试 |
| IS NOT NULL | NOT NULL 值测试 |
| LIKE | 模式匹配 |
| NOT LIKE | 否定匹配 |
例如,我们查询,年龄在 20~50 岁的学生。
mysql> SELECT * FROM student WHERE s_age BETWEEN 20 AND 50;
+------+---------------+-------+-------+
| s_id | s_name | s_sex | s_age |
+------+---------------+-------+-------+
| 1002 | shiyanlou1002 | woman | 20 |
| 1004 | shiyanlou1005 | woman | 40 |
+------+---------------+-------+-------+
除此之外,我们还可以使用多个表达式进行逻辑运算
| 逻辑运算符 | 释义 | ||
|---|---|---|---|
| OR,\ | \ | 或 | |
| AND,&& | 与 | ||
| NOT,! | 非 | ||
| XOR | 异或 |
例如,我们也可以通过 AND 查找年龄在 20~50 岁的学生。
mysql> SELECT * FROM student WHERE s_age>=20 AND s_age<=50;
+------+---------------+-------+-------+
| s_id | s_name | s_sex | s_age |
+------+---------------+-------+-------+
| 1002 | shiyanlou1002 | woman | 20 |
| 1004 | shiyanlou1005 | woman | 40 |
+------+---------------+-------+-------+
除了上述所列举的运算符和表达式之外,我们还可以进行一些数学的计算操作,例如加减乘除等,如下示例,我们将 student 表中的 s_id 和 s_age 分别进行加减乘除操作。
mysql> SELECT s_id,s_age,s_id+s_age,s_id-s_age,s_id*s_age,s_id/s_age FROM student;
+------+-------+------------+------------+------------+------------+
| s_id | s_age | s_id+s_age | s_id-s_age | s_id*s_age | s_id/s_age |
+------+-------+------------+------------+------------+------------+
| 1001 | 10 | 1011 | 991 | 10010 | 100.1000 |
| 1002 | 20 | 1022 | 982 | 20040 | 50.1000 |
| 1003 | 18 | 1021 | 985 | 18054 | 55.7222 |
| 1004 | 40 | 1044 | 964 | 40160 | 25.1000 |
| 1005 | 17 | 1022 | 988 | 17085 | 59.1176 |
+------+-------+------------+------------+------------+------------+
5. 通配符
在上述内容中,我们有提到 LIKE,它是一个字符串比较函数,用于 LIKE 有两个通配符:
- % 百分号,匹配任意数量的字符
- _ 下划线,匹配一个字符
例如,我们查看学生表中 s_name 以 2 结尾的学生信息,如下:
mysql> SELECT * FROM student WHERE s_name LIKE "%2";
+------+---------------+-------+-------+
| s_id | s_name | s_sex | s_age |
+------+---------------+-------+-------+
| 1002 | shiyanlou1002 | woman | 20 |
+------+---------------+-------+-------+
6. 函数
MySQL 中有很多函数,这里我们仅仅介绍一些常用的内容。
6.1 MAX 和 MIN 查找列的最大值和最小值。例如查找学生表中的年龄的最大值和最小值:
mysql> SELECT max(s_age),min(s_age) FROM student;
+------------+------------+
| max(s_age) | min(s_age) |
+------------+------------+
| 40 | 10 |
+------------+------------+
6.2 SUM 及 AVG SUM 和 AVG 分别可以用来求和以及求平均值。
例如,查找选课表中,s_id=1001 学生成绩的总分及平均值:
mysql> SELECT avg(grade),sum(grade) FROM sc WHERE s_id="1001";
+------------+------------+
| avg(grade) | sum(grade) |
+------------+------------+
| 62.0000 | 186 |
+------------+------------+
除此之外,我们还可以使用 DISTINCT 修饰符指定从结果集中删除重复的行,对应的是 ALL ,为默认项。通过如下示例来了解:
mysql> SELECT grade FROM sc;
+-------+
| grade |
+-------+
| 20 |
| 70 |
| 96 |
| 100 |
| 80 |
| 80 |
| 75 |
+-------+
7 rows in set (0.00 sec)
# 重复的 80 的记录会被删除
mysql> SELECT DISTINCT grade FROM sc;
+-------+
| grade |
+-------+
| 20 |
| 70 |
| 96 |
| 100 |
| 80 |
| 75 |
+-------+
6.3 COUNT
COUNT 函数用于计数
例如,我们统计选课表中 s_id=1001 有多少条记录,就可以使用 count
mysql> SELECT s_id,count(s_id) FROM sc WHERE s_id=1001;
+------+-------------+
| s_id | count(s_id) |
+------+-------------+
| 1001 | 3 |
+------+-------------+
6.4 CONCAT
CONCAT 是一个字符串函数。
在上面的内容中我们介绍了一些数值的计算,不仅如此,我们还可以进行字段的拼接操作。
例如,我们有两个字符串 shiyanlou 和 MM ,想将其拼接为 shiyanlouMM,标准 SQL 语句中,我们可以直接使用 SELECT "shiyanlou" + "MM" 或者 SELECT "shiyanlou" || "MM" 即可,但是在 MySQL 中,我们需要借助 CONCAT 函数,如下示例:
mysql> SELECT concat("shiyanlou","MM");
+--------------------------+
| concat("shiyanlou","MM") |
+--------------------------+
| shiyanlouMM |
+--------------------------+
1 row in set (0.04 sec)
mysql> SELECT concat("",s_id,"") FROM student;
+------------------------+
| concat("",s_id,"") |
+------------------------+
| 1001 |
| 1002 |
| 1003 |
| 1004 |
| 1005 |
+------------------------+
除此之外, MySQL中所拥有的函数数不胜数,这里,我们希望大家能够通过上面列举出的函数学会 MySQL 中函数的简单使用方法。
7. 分组排序
关于分组我们会学习到 SELECT 的两个子句,分别为:
- GROUP BY
- HAVING
详细的语法格式对于初学者来说并不友好,下面我们通过实例来讲解相关的内容。
7.1 GROUP BY
分组(GROUP BY) 功能,有时也称聚合,一些函数可以对分组数据进行操作,例如我们上述所列的 AVG SUM 都有相关的功能,不过我们并未使用分组,所以默认使用所有的数据进行操作。首先我们描述聚合的使用方法:
[GROUP BY {col_name | expr | position} [ASC | DESC], ...]
如上所述,分组的标准可以为以下三种:
- 字段名(col_name)
- 表达式(expr)
- 位置(position)。
我们可以选择上面的一种进行分组,也可以重复多个,或者综合使用。
例如,我们根据字段名 s_id 进行分组:
mysql> SELECT * FROM sc GROUP BY s_id;
+------+------+-------+
| s_id | c_id | grade |
+------+------+-------+
| 1001 | 1 | 20 |
| 1002 | 1 | 100 |
| 1003 | 3 | 75 |
+------+------+-------+
如上所示,我们根据学生 id ,即 s_id 进行分组后,我们便只能查看到不同学生的第一条数据,不会有重复的 s_id 记录显示,我们可以尝试去掉 GROUP BY 字句做对比。
但是这样查询出来的数据意义不大,所以我们经常会搭配使用一些能够对一组数据进行操作的函数,例如,我们根据 s_id 进行分组后查询学生的总成绩,使用 SUM 函数:
mysql> SELECT s_id,sum(grade) FROM sc GROUP BY s_id;
+------+------------+
| s_id | sum(grade) |
+------+------------+
| 1001 | 186 |
| 1002 | 260 |
| 1003 | 75 |
+------+------------+
除此之外,我们还可以使用 ASC 或者 DESC 描述符来指定升序或者降序显示结果集,ASC 是默认选项,我们以 DESC 做如下示例:
mysql> SELECT s_id,sum(grade) FROM sc GROUP BY s_id DESC;
+------+------------+
| s_id | sum(grade) |
+------+------------+
| 1003 | 75 |
| 1002 | 260 |
| 1001 | 186 |
+------+------------+
上面是使用 col_name 的方式,这里我们还可以使用表达式的方式,更明确的指定筛选的条件:
mysql> SELECT sum(grade) FROM sc GROUP BY s_id=1001;
+------------+
| sum(grade) |
+------------+
| 335 |
| 186 |
+------------+
如上所示的使用表达式的方式,第一行数据代表 s_id 不等于 1001 的成绩之和,第二行代表 s_id 等于 1001 的成绩之和。
最后一种使用位置参数的方式,这里的位置参数代表的是要查询字段的位置,如下所示,1 对应 c_id。
mysql> SELECT c_id,sum(grade) FROM sc GROUP BY 1;
+------+------------+
| c_id | sum(grade) |
+------+------------+
| 1 | 120 |
| 2 | 80 |
| 3 | 145 |
| 4 | 176 |
+------+------------+
另外,我们还可以多个组合在一起使用,对于我们的选课表 sc 而言,如果使用 s_id 以及 c_id 进行分组,则得到的是所有的数据,因为我们使用 s_id 以及 c_id 作为主键,所以因此不会有相同的一组值可以进行分组,得到的是全部的数据。
如语法中所示,多个一起使用时使用 逗号 进行分隔。这里我们使用 s_id 以及 grade 一起作为分组的标准,如下所示:
mysql> SELECT s_id, c_id, grade, sum(grade) FROM sc GROUP BY s_id,grade;
+------+------+-------+------------+
| s_id | c_id | grade | sum(grade) |
+------+------+-------+------------+
| 1001 | 1 | 20 | 20 |
| 1001 | 3 | 70 | 70 |
| 1001 | 4 | 96 | 96 |
| 1002 | 2 | 80 | 160 |
| 1002 | 1 | 100 | 100 |
| 1003 | 3 | 75 | 75 |
+------+------+-------+------------+
7.2 HAVING
除了可以对数据进行分组之外,我们还可以对分组数据进行过滤,使用 HAVING 子句,HAVING 跟 WHERE 的用法类似。两者在大多数时候都能起到相同的作用,如下示例
mysql> SELECT * FROM student HAVING s_id=1001;
+------+---------------+-------+-------+
| s_id | s_name | s_sex | s_age |
+------+---------------+-------+-------+
| 1001 | shiyanlou1001 | man | 10 |
+------+---------------+-------+-------+
1 row in set (0.00 sec)
mysql> SELECT * FROM student WHERE s_id=1001;
+------+---------------+-------+-------+
| s_id | s_name | s_sex | s_age |
+------+---------------+-------+-------+
| 1001 | shiyanlou1001 | man | 10 |
+------+---------------+-------+-------+
1 row in set (0.00 sec)
但是对于 HAVING 和 WHERE 来讲,HAVING 可以引用 SUM AVG 等函数,而 WHERE 则不能,即 HAVING 一般针对 分组,而 WHERE 针对的是 行。即便很多时候两者都能起到同样的作用,你也不应该混用他们。
如下示例,我们从选课表中筛选出选课总成绩大于 100 分的学生:
mysql> SELECT s_id, sum(grade) FROM sc GROUP BY s_id HAVING sum(grade)>100;
+------+------------+
| s_id | sum(grade) |
+------+------------+
| 1001 | 186 |
| 1002 | 260 |
+------+------------+
7.3 ORDER BY
ORDER BY 用于对数据进行排序,使用方式跟 GROUP BY 一样:
[ORDER BY {col_name | expr | position} [ASC | DESC], ...]
这里我们可以将上述的查询语法,分组,以及排序综合起来,如下所示:
SELECT [ALL | DISTINCT]
col_name[,col_name...] FROM tbl_name [WHERE where_condition]
[GROUP BY {col_name | expr | position} [ASC | DESC], ...]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC], ...]
上面的示例有一些复杂,部分子句并不是必须项,不过我们可以大致总结出 SELECT 子句的使用顺序,如下:
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
下面我们来综合示例,例如,我们将选课表 sc 的数据根据 s_id 进行分组,获得 s_id 以及对应的总成绩 sum(grade) 列,并给 sum(grade) 取一个别名为 sum_grade,然后筛选出 sum_grade >100 的分组,并且根据 sum_grade 进行降序排序,如下:
mysql> SELECT s_id,sum(grade) AS sum_grade FROM sc GROUP BY s_id HAVING sum_grade>100 ORDER BY sum_grade DESC;
+------+-----------+
| s_id | sum_grade |
+------+-----------+
| 1002 | 260 |
| 1001 | 186 |
+------+-----------+
由于在选课表中,我们的数据并不够多,使用不同的分组方式和排序方式显示的结果并不够直观,但是对于了解分组和排序的操作来说已经足够,同学们可以自己运用前面学习的插入操作,插入更多的数据,来进行分组和排序的练习。
7.4 LIMIT
最后,我们还可以对返回的结果集进行限制,使用 LIMIT 。
LIMIT 可以使用一个或者两个非负的整数作为参数,他们的区别如下:
LIMIT 2 代表返回结果集的前 2 行
LIMIT 2,3 代表从第三行开始(因为下标从 0 开始,所以这里的 2 代表第三行),返回接下来的三行内容,即 3,4,5 行。
如下示例:
mysql> SELECT * FROM student LIMIT 2;
+------+---------------+-------+-------+
| s_id | s_name | s_sex | s_age |
+------+---------------+-------+-------+
| 1001 | shiyanlou1001 | man | 10 |
| 1002 | shiyanlou1002 | woman | 20 |
+------+---------------+-------+-------+
2 rows in set (0.00 sec)
mysql> SELECT * FROM student LIMIT 2,3;
+------+---------------+-------+-------+
| s_id | s_name | s_sex | s_age |
+------+---------------+-------+-------+
| 1003 | shiyanlou1003 | man | 18 |
| 1004 | shiyanlou1005 | woman | 40 |
| 1005 | shiyanlou1005 | man | 17 |
+------+---------------+-------+-------+
8. 子查询
在上面的内容中,关于查询的语法已经足够复杂,虽然对于完整的内容来说还稍显不足,但是,为了不再增加该语句的复杂性,这里,我们不再给出语法结构,而是讲解示例。
子查询又被称为嵌套查询,如下示例:
我们要查询选修了课程的课程号 c_id 为 1 的学生的年龄:
- 首先我们需要从选课表sc 中查询,选修课程号 c_id 为 1 的学生的学号:
mysql> SELECT s_id FROM sc WHERE c_id=1;
+------+
| s_id |
+------+
| 1001 |
| 1002 |
+------+
- 接着我们可以使用获得的学生号去查询年龄字段,从而得到最终的结果:
mysql> SELECT s_id,s_age FROM student WHERE s_id IN (1001,1002);
+------+-------+
| s_id | s_age |
+------+-------+
| 1001 | 10 |
| 1002 | 20 |
+------+-------+
上面的查询过程分为两步,而使用子查询我们只需要一步,如下:
mysql> SELECT s_id,s_age FROM student WHERE s_id IN (SELECT s_id FROM sc WHERE c_id=1);
+------+-------+
| s_id | s_age |
+------+-------+
| 1001 | 10 |
| 1002 | 20 |
+------+-------+
即将第一步的查询嵌入第二步的操作中,并且将第一步查询的结果用于第二步查询的判断条件中。
类似的操作还有很多,下面我给出一个使用子查询的例子,大家可以分析其代表的含义,并且考虑有没有更简单的实现方式:
SELECT * FROM student WHERE s_id IN (SELECT s_id FROM sc WHERE c_id=(SELECT c_id FROM course WHERE c_time=(SELECT max(c_time) FROM course)));
select 语句查询数据操作视频:
9. 总结
在本节的内容中我们介绍了很多关于查询的相关内容。